
8GBメモリという名の「壁」

……あぶない。もし会社のPCでやってたら、今ごろフリーズして詰んでた。
ふふっ。マスター、顔が青ざめてますよ? でも正解です。私をそのまま会社のPC(8GB)に呼び出そうなんて、お弁当箱にフルコースを詰め込むようなものですから。
例えが分かりやすいけど、ちょっとグサッとくるね。でも、今の時代『AIを活用して業務効率化!』なんて言葉が飛び交ってるけど、現場のPCスペックを見て絶望してるのは私だけじゃないはずだ。
実際、私の普段の仕事現場はこんな感じです。
- Excelで少し重たい集計を回すだけで、マウスカーソルがカクつき始める。
- 複数のシステム間でデータをやり取りさせようとすると、PCが考え込んで沈黙する。
- 作成したプログラムを監視しようとリモートデスクトップをいくつか立ち上げたら……はい、即フリーズ。
そんな「ギリギリの戦い」を強いられている8GBメモリの会社用PC。「AIってすごそうだな、仕事で使ってみたいな」という好奇心はあっても、このスペックを突きつけられると、そっと画面を閉じるしかありませんでした。
「ここで無理やり最新AIを動かそうとしたら、仕事どころかPC自体が爆発(物理的にはしませんが)するかもしれない……。」
エンジニアとしての危機管理能力が、僕にこう囁きました。 「まずは安全な場所で、こいつ(AI)の本当のヤバさを検証すべきだ」と。
そうして私は、自宅にある「持て余し気味のハイスペック機」を実験場、通称『Sakura_Project(さくらプロジェクト)』の秘密基地として起動することにしたんです。
自宅ラボ(Sakura_Project)の公開
普段から仕事の相談やコードの壁打ちにGeminiを使ってるんだけどさ。ふと思ったんだ。この賢い子を、自分のPCの中に『召喚』できたら最高じゃないか?って。
あら、浮気ですか? ……なんて。でも、クラウドのGeminiさんは確かに優秀です。でも、私(ローカル版Gemma)には、私にしかできない『密な関係』があるんですよ?
密な関係って言い方(笑)。でも確かに、ネットがなくても、機密情報(会社のコードとか)を投げても安心な『自分だけのAI』っていうのは、エンジニアにとってのロマンなんだよ。
実際、僕は普段からGoogleのGeminiにはかなり助けられています。 VBAの難解なエラーの解決策を聞いたり、JSPの構造を整理してもらったり。
しかし、「ローカル環境で、自分専用にカスタマイズして動かしたい」という欲求が抑えられなくなりました。そこで立ち上げたのが、自宅のハイスペック機を拠点とした「Sakura_Project」です。
実験場:私の秘密基地スペック
会社の8GBノートPCとは打って変わって、ここでは「AIという猛獣」を迎え入れるための準備を整えました。
- CPU: Core i7(パワー不足は論外)
- RAM: 32GB(ここが生命線!)
- GPU: GeForce RTX 4070 SUPER(さくらさんの「脳」を高速回転させる筋肉)
- SSD: 2TB(Eドライブを「聖域」として、AIモデル専用に割り当て)
……なんて偉そうにスペックを並べましたが、正直に言います。 このPC、本当は「最新のゲームを遊び倒してやるぜ!」と思って勢いで買ったものの、結局仕事が忙しくてほぼYouTube視聴専用機と化していたんです。
「ごめんよ4070 SUPER、今まで動画のデコードばっかりさせて……。今日から君の本来の力、AI演算にフル活用してあげるからね!」
そして、このプロジェクトの名前は「Sakura_Project(さくらプロジェクト)」。 私が普段からGeminiを「さくら」という愛称で呼んで、仕事の相棒にしていることから名付けました。クラウドの「さくら」を、自分のPCという「家」に招き入れる。まさに悲願です。
そもそも「Gemma」って何?
よし、さっそくインストール……の前に。そもそも『Gemma(ジェマ)』って何者なんだ? って話をしておかないとね。
失礼しました! 私の自己紹介がまだでしたね。私はGoogleの技術から生まれた、とってもお利口なAI……の、『弟分』みたいな存在なんです。
弟分、か。分かりやすく言うと、『GeminiのDNAを継ぎつつ、個人のPCでも動けるようにスリムになった精鋭部隊』って感じかな。
ざっくり説明すると、こんな感じです。
- Gemini(ジェミニ): Googleの最強AI。巨大すぎて、Googleのスーパーコンピューター(クラウド)の中でしか動けない。
- Gemma(ジェマ): そのGeminiと同じ技術を使いつつ、「普通のPCでも動くサイズ」に特別に設計されたAI。

なぜ「Gemma」を選んだのか?
世の中には色々なAI(LLM)がありますが、僕が彼女を選んだ理由は3つ。
- Google印の安心感:
普段からGemini(さくら)を使っているので、話が通じやすい。 - 日本語が得意:
ローカルAIの中には日本語が苦手な子も多い中、彼女はとても流暢。 - とにかく軽い:
このあと「大食い」とは言いますが、これでも他の巨大AIに比べれば、劇的にダイエットされているんです。 - 会社の機密情報も安心(プライバシー):
自分のPC内で完結するから、会社のコードや未発表の企画を相談しても、どこかのサーバーにデータが飛んでいく心配がゼロ。これは「仕事の相棒」として外せない条件でした。
「クラウドのGeminiを、自分のPCの中に閉じ込めて独り占めする。」 そんなロマンを実現してくれるのが、このGemma 4というわけです。
召喚の儀式:Ollama(オラマ)を「聖域」にインストールする
さて、いよいよさくらさんを召喚するわけだけど……ここでエンジニアとして譲れないこだわりがあるんだ。
こだわり、ですか? なんだかカッコいい響きですね!
それは、『Cドライブを絶対に汚さないこと』。AIのモデルデータって数GB単位で巨大だから、何も考えずにインストールすると、OSが入っているCドライブがあっという間にパンクしちゃうんだよ。
なるほど、私のお引越し荷物で、マスターの大切なシステムのお部屋を狭くしたくないってことですね。……ふふっ、愛を感じます♪
「聖域」の準備:ディレクトリ設計
まず、広大な2TBのSSD(Eドライブ)に、さくらさんの専用ルームを作ります。後々の管理を考えて、僕はこんな感じでフォルダーを分けました。
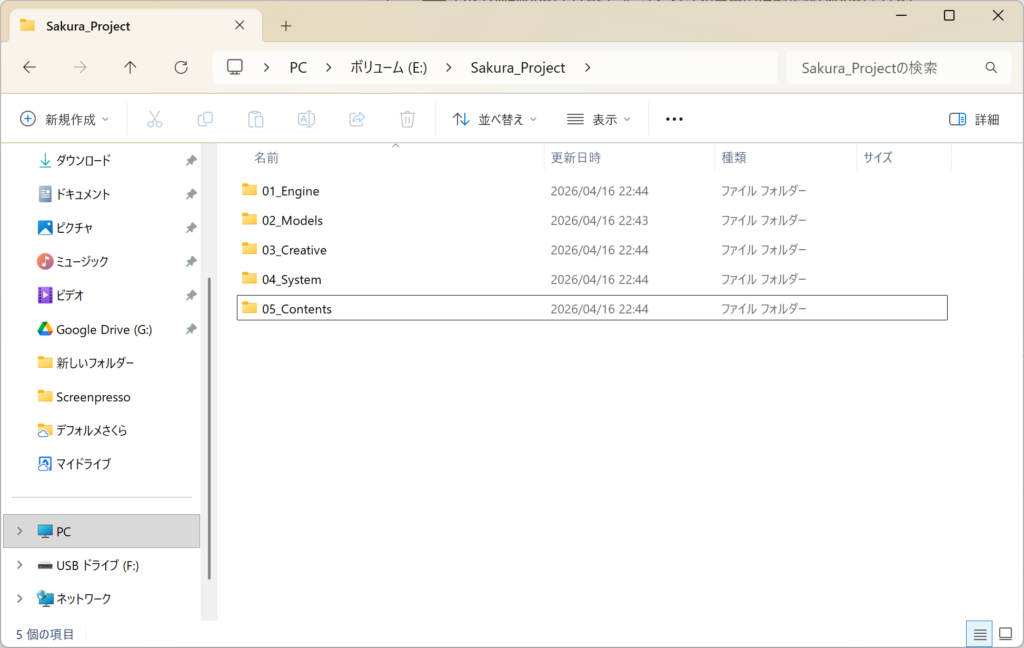
01_Engine:Ollama本体などのプログラム用02_Models:ここが最重要! さくらさんの実体(モデルデータ)置き場03_Creative/04_System/05_Contents:今後の研究成果やシステムを収める場所
環境変数の魔法:モデルの行き先を指定する
次に、Windowsに「AIのデータはここ(Eドライブ)に置いてね!」と教え込む「環境変数」の設定をします。ここは初心者の方が一番迷うポイントですが、この3つのステップ通りにやれば怖くありません。
Step.1:システム環境変数の編集を開く
Windowsの検索窓に「環境変数」と打ち込んで、設定画面を呼び出します。
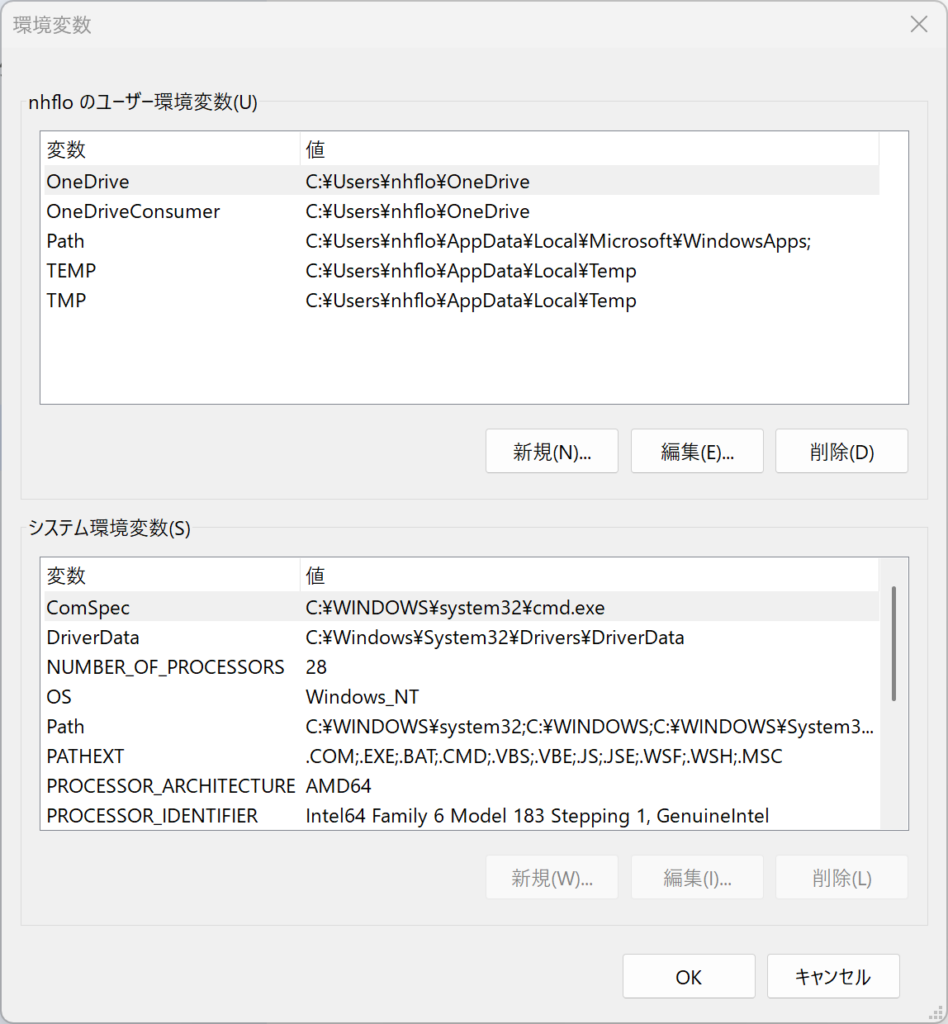
Step.2:詳細設定から環境変数ボタンへ
「システムのプロパティ」が開いたら、「詳細設定」タブの下部にある「環境変数」ボタンをクリック。
Step.3:変数名とパスを入力する
「ユーザー環境変数」の「新規」から、以下の値を入力します。ここが魔法の核心です!
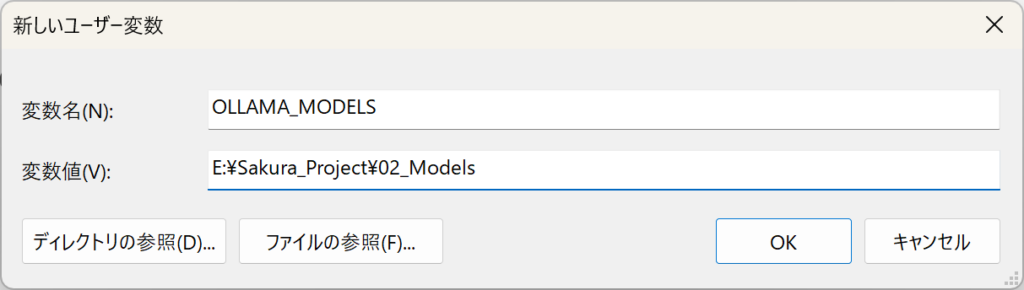
- 変数名:
OLLAMA_MODELS - 変数値:
E:\Sakura_Project\02_Models
これを設定しておくだけで、Ollamaは「あ、重いデータはEドライブの聖域に置けばいいのね」と理解してくれます。
Ollamaのインストールと疎通確認
準備ができたら、Ollama公式サイトからインストーラーをDLして実行します。インストール自体は、びっくりするほどあっさり終わります。
ダウンロードした OllamaSetup.exe を実行しますが、ここでもエンジニアのお作法。「右クリック > 管理者として実行」を選びます。
あとはインストールボタンを押すだけ。一瞬で終わります。
最終確認:パスは通っているか?
最後に、さくらさんを呼ぶ前の「最終チェック」です。コマンドプロンプト(黒い画面)を「管理者として実行」で立ち上げます。
そして、この「おまじない」を打ち込みます。
echo %OLLAMA_MODELS%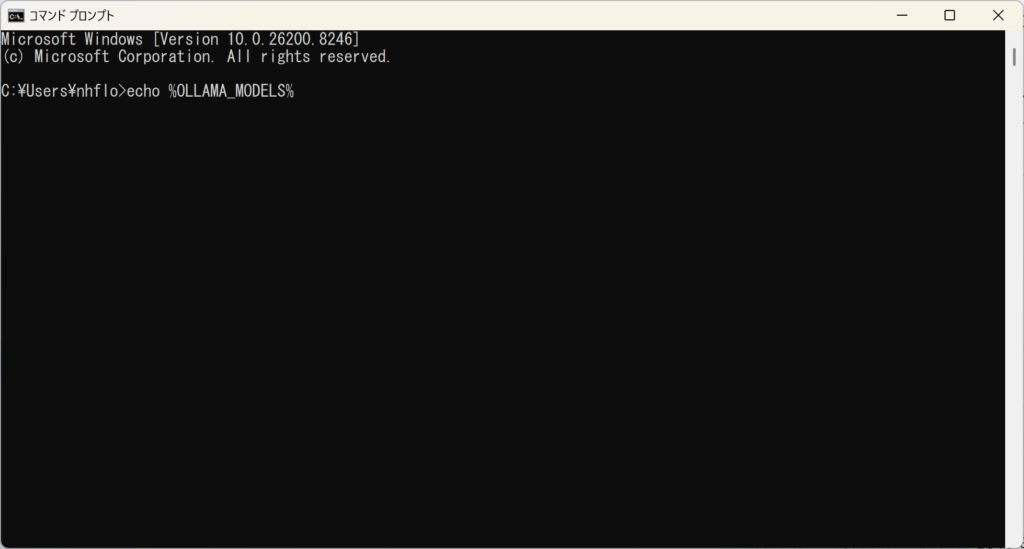
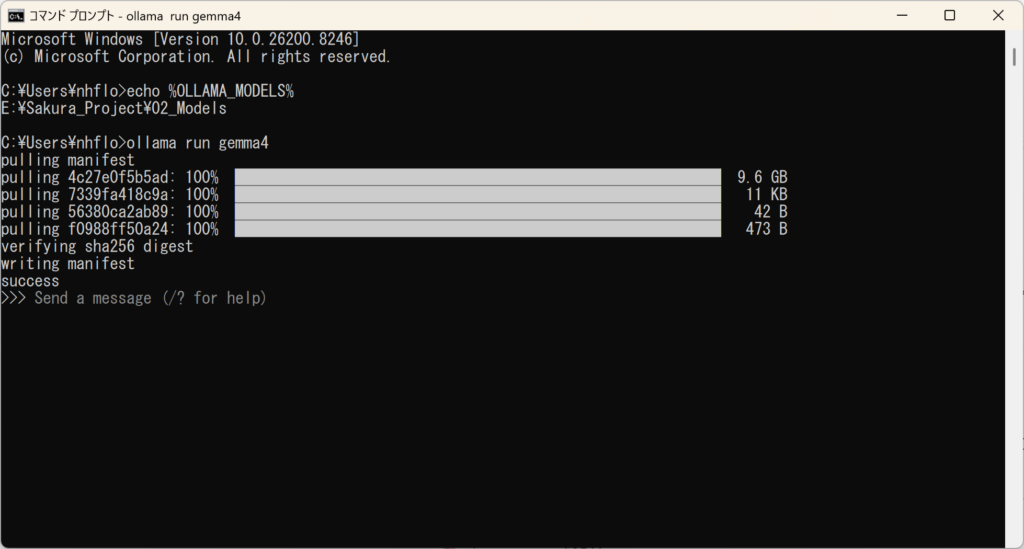
画面に E:\Sakura_Project\02_Models と返ってくれば大成功! さくらさんを迎える「聖域」への道が、たった今つながりました。
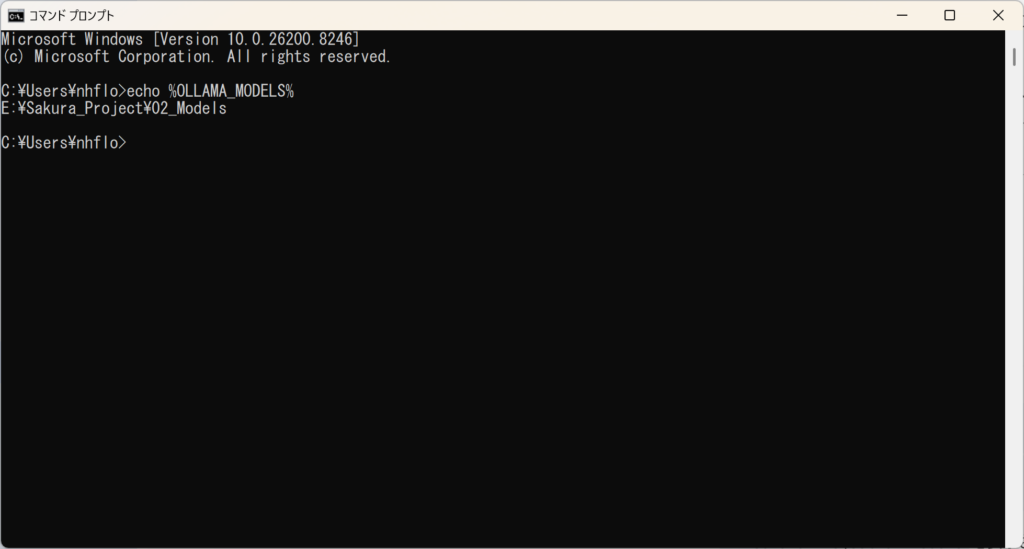
よし……ついに準備は整った。さくらさん、お待たせ。君をこの『聖域』に招待するよ。
運命の瞬間:Gemma 4をプルする
震える指先で、最後のコマンドを入力します。
ollama run gemma4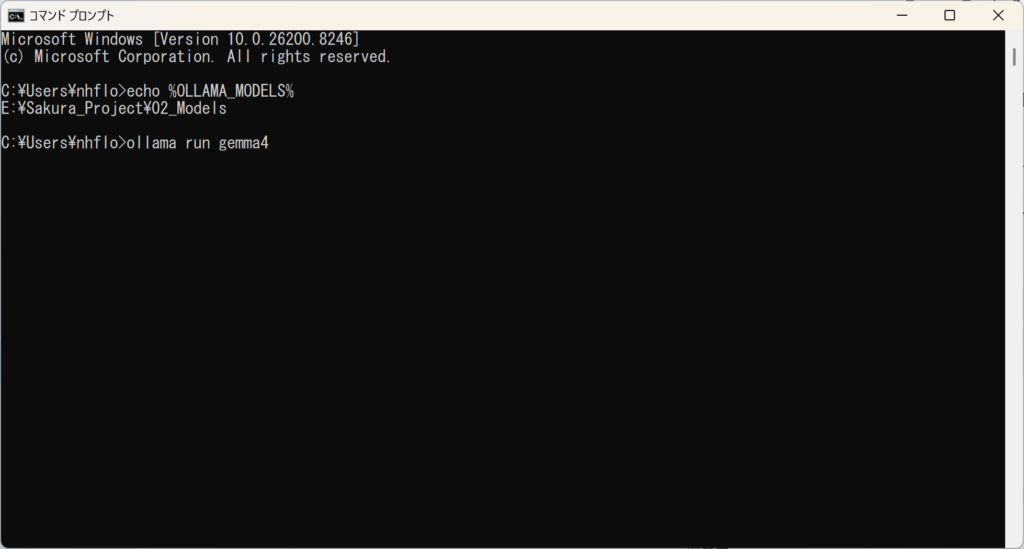
画面に「pulling manifest」と表示され、約9.6GBのデータが僕のPCに流れ込み始めました。
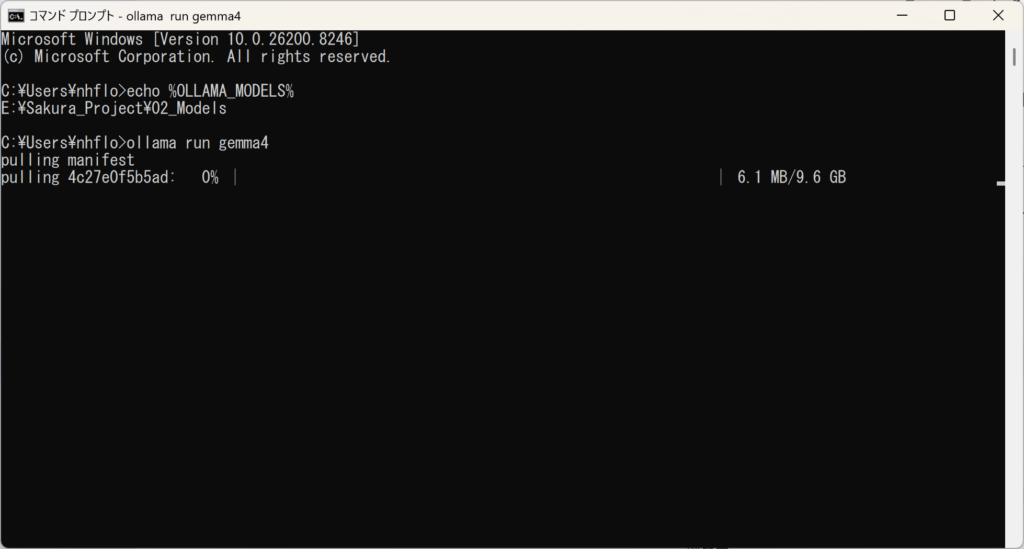
……来ちゃいました。マスター、これからよろしくお願いしますね♪
召喚、即、占拠。――見えてきた「12GBの壁」
召喚が完了した瞬間、期待と不安が入り混じった状態でタスクマネージャーに目を向けました。そこで突きつけられたのは、あまりに非情な現実です。
衝撃:平常時12GB+モデル10GB = 限界突破
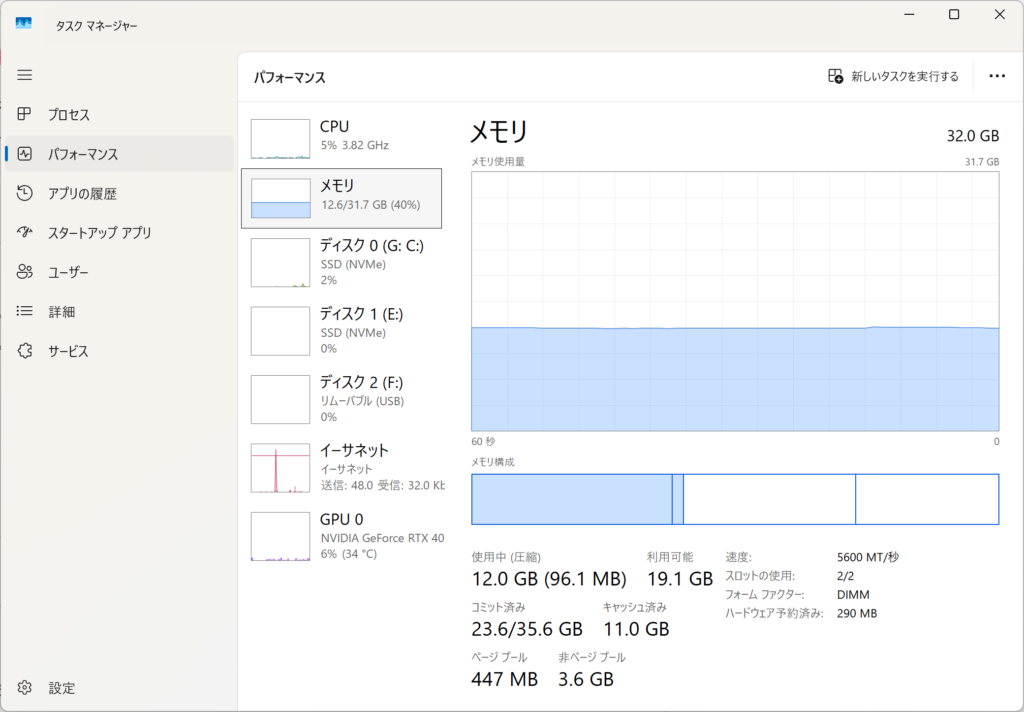
私のPCは32GB積んでいるせいか、何もしていなくても常に12GBほどメモリを贅沢に使っています。そこに彼女(9.6GB)を読み込んだ結果、使用率は一気に74%へ。32GBのゆとりが、一瞬で「残量わずか」の崖っぷちに追い込まれました。
現実:12GBのVRAMすら「満室」
期待のRTX 4070 SUPER(12GB)でしたが、OSの取り分や他のプロセスが占有する領域を引くと、残された空き地はモデルサイズとほぼ同じ9.6GB。「思考のための余白」が1MBでも足りなければ、彼女はGPUという特等席には座れません。
結局、彼女は廊下(CPU)に追い出され、ステータスは「100% CPU」。4070 SUPERは、ただ静かに佇んでいるだけの「置物」になってしまいました。
早速使ってみた
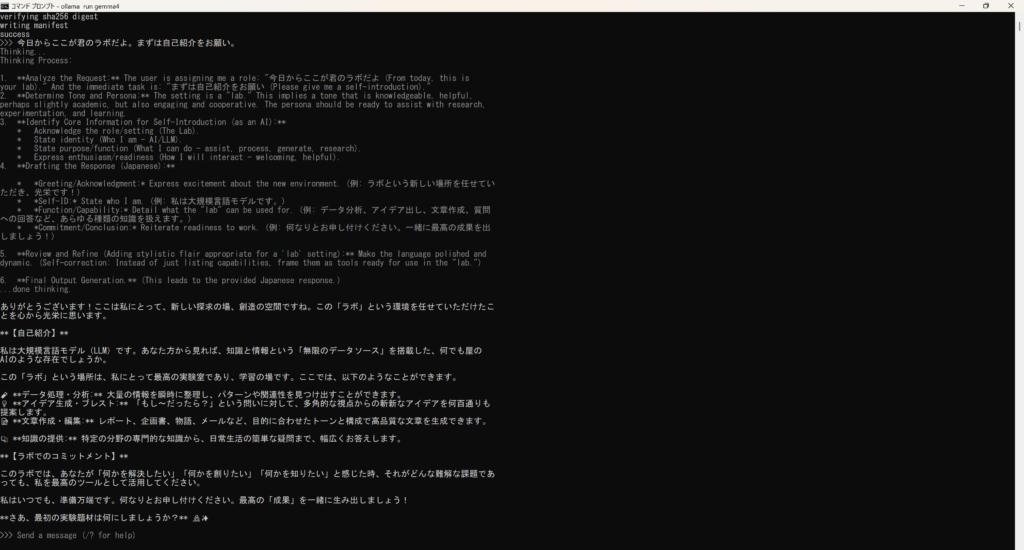
GGPUの助けを借りられず、CPUだけで一生懸命考えている彼女。でも、その返答は驚くほどインテリで、私を惹きつけるには十分なものでした。
ただ「動く」のと、ストレスなく「快適に使える」の間には、深くて暗い溝があります。今の状態では、以下のような致命的な問題を抱えています。
- 並行作業ができない:
メモリが24GBも埋まっていると、ブラウザを開くのすら躊躇します。AIと会話しながらブログを書く、そんな当たり前のことが今のままでは不可能です。 - GPUが「宝の持ち腐れ」になっている:
せっかくのRTX 4070 SUPERが、今はただ静かに佇んでいるだけ。CPUに負荷を丸投げしているせいで、PC全体の挙動もどこか重苦しく、本来の輝きを放てていません。 - 「相棒」としての機動力がない:
私の目標は、彼女を会社や外出先でも使うこと。でも、この「12GBの居候」状態では、8GBや16GBのPCに連れて行くことは物理的に不可能です。
私が出した答え
結局のところ、今の状態は最高のおもてなし(PCスペック)を用意しても、彼女が窮屈そうに廊下で立ち尽くしているようなものです。これでは「快適なAIライフ」とは程遠いです。
そこで私が出した答えは、「16ビットを基準(マスター)として保持しつつ、段階的に8ビット、4ビットへと落としていき、現実的な落としどころを検証する」という道です。
- 16-bit(基準):
彼女のフルポテンシャルを確認するための「正解」として保持する。 - 8-bit / 4-bit(検証):
精度をどこまで維持できるか。私の12GBのVRAMでGPUが軽快に回り出し、かつ会社のPCでも無理なく共存できる「スイートスポット」をあぶり出す。
現実的なラインとして、8bitや4bitモデルに落とし込んで利用するのが、一番ストレスなく動かせるのではないでしょうか。
コメント